Хранилища данных - статьи
Беспроводная OLAP-модель
На рис. 1 показана архитектура среды, в которой трансляция данных происходит по запросу пользователей. Эта схема в наибольшей мере подходит для поддержки беспроводной обработки OLAP-запросов. Функции сервера состоят в поддержке и распространении сводных таблиц. Интересно, что проблема планирования трансляции, возникающая в беспроводных OLAP-системах, характеризуется вышеупомянутой особенностью — зависимостью извлечения. Иными словами, каждый клиентский запрос направлен на одну сводную таблицу, но эта таблица может включать в себя другую сводную таблицу, запрашиваемую иным клиентом. Однако каждая таблица, отвечающая определенному запросу, требует некоторых затрат на обработку, и при выборе конкретной таблицы для трансляции необходимо эти издержки учитывать.
Так как для эффективной рассылки данных общие алгоритмы планирования доставки часто используют агрегирование запросов, то зависимость извлечения дает дополнительную возможность оптимизации, повышая производительность и масштабируемость.
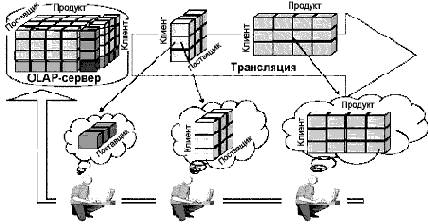
Рис.1. Беспроводная OLAP-система
Например (см. рис. 1), зафиксировав значение по измерению «Клиент» из детализированной таблицы («Поставщик – Клиент») можно получить абстрактную таблицу («Поставщик»).
Таким образом, идея использования сводных таблиц для выведения одних таблиц из других используется довольно широко. Ее смысл состоит в выборе надлежащего набора таблиц для хранения, чтобы повысить скорость обработки запросов, учитывая пространственные ограничения.
Для упрощения процесса выбора используется решетка поиска, которая представляет собой направленный граф, отображающий пространство подкубов, между которыми фиксируются зависимости извлечения. Например на рис. 2 показана решетка для схемы «Поставщик (ПС) – Продукт (ПР) – Клиент (К)».
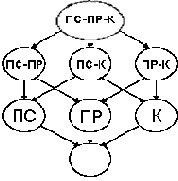
Рис.2. Решетка Кубов Данных
Зависимость извлечения сводных таблиц и идея решетки поиска применяется при выборе таблиц при трансляции в беспроводных каналах для минимизации времени ожидания ответа на запрос пользователя.
В этом случае предполагается, что все решетки подкубов хранятся на сервере (такое допущение разумно, особенно для относительно небольших витрин данных). Клиент посылает запрос на таблицу по каналу восходящей связи. Затем он прослушивает канал нисходящей связи в ожидании ответа. Клиент может находиться в одном из двух режимов:
Выполнение запросов клиентов полностью зависит от сервера, доступ к локальному хранилищу и кэширование предыдущих ответов для последующего использования не осуществляется.
Минимальная единица трансляции называется пакетом (packet) или сегментом (bucket). Транслируемая таблица разделяется на одинаковые по размеру пакеты, первый из которых называют пакетом-дескриптором (descriptor). В заголовке пакета передаются данные или дескриптор, а также расстояние (временной интервал) до начала следующего пакета-дескриптора и расстояние от начала дескриптора до пакета. Пакет-дескриптор содержит таблицу с идентификатором, описывающим агрегируемые измерения транслируемой таблицы, количество значений атрибутов или кортежей и количество пакетов данных, составляющих эту таблицу.
Период передачи таблицы называют циклом трансляции (broadcast cycle): каждая таблица передается в течение определенного цикла, который начинается с момента трансляции пакета-дескриптора. Длительности циклов для разных таблиц при этом могут различаться.
Пусть запрос в восходящий канал связи Q характеризуется набором Group-By атрибутов D. Тогда запрос представим как QD, а соответствующую ему таблицу как TD. Сводная таблица TD1 включает в себя таблицу TD2, если D2
D1, или, другими словами, TD2 зависит от TD1. Обозначим количество атрибутов (измерений) в множестве D как |D|.
Посылая в канал восходящей связи запрос на некоторую таблицу TR, клиент сразу же настраивается на нисходящий канал в поиске пакетов-дескрипоторов.
Обнаружив такой пакет, клиент классифицирует содержащуюся в нем таблицу (пусть это будет TB) следующим образом:
B и R ? B).
B.
Например: пусть R = («Поставщик – Продукт»), тогда B1 = («Поставщик – Продукт – Клиент») включает R, а для B2 = («Продукт») и B3 = («Поставщик – Клиент») не имеется соответствия. В зависимости от типа соответствия клиент будет либо настраиваться на получение дальнейшей последовательности пакетов для чтения таблицы TB, либо ожидать следующего цикла трансляции.