Хранилища данных - статьи
Алгоритмы планирования
Для решения проблемы трансляции данных в беспроводной среде было предложено несколько алгоритмов-планировщиков, эффективность которых можно оценить по следующим показателям:
В представленной модели запросы поступают на разные таблицы, размеры которых могут отличаться. Поэтому одинаковое качество обслуживания для всех запросов невозможно и нецелесообразно. С другой стороны, запросы можно логически сгруппировать в классы, качество сервиса для каждого из которых будет разным. Таким образом, эффективность алгоритма будет характеризовать показатель доступности (для его расчета используется дополнительные показатели):
Время обслуживания зависит от размера таблицы, и, следовательно, за счет параметра stretch удается нормализовать значение времени доступа относительно размера таблицы. Низкое значение стандартного отклонения указывает на правильно выбранную методику планирования задач трансляции, а высокое значение говорит о том, что для некоторого класса таблиц трансляция ведется не в оптимальном режиме.
Рассмотрим подробнее пять основных алгоритмов-планировщиков:
Первым прибыл — первым обслужен (ПППО). Этот простой метод планирования предполагает, что запросы обслуживаются и транслируются по мере их поступления.
Первым — с наименьшим временем обслуживания (ПСВО). В первую очередь планировщик обслуживает тот элемент данных, который требует минимальных ресурсов. В нашем случае в качестве ресурса выступает канал нисходящей связи. Поэтому первым транслируется элемент данных с минимальным размером.
Первыми — самые популярные запросы (ПСПЗ). В первую очередь планировщик выбирает для трансляции тот элемент данных, на который поступило максимальное количество запросов.
RxW. В этой схеме используются преимущества ПСПЗ и ПППО. В каждом цикле трансляции сервер выбирает некоторый элемент с максимальным значением параметра R×W, где R — количество запросов на этот элемент, W — максимальное время ожидания ответа на запрос.
Описанные выше алгоритмы-планировщики в некоторых случаях работают хорошо, а в некоторых не дают приемлемых результатов. Выбор планировщика трансляции тесно связан с особенностями конкретного приложения, в котором могут применяться особые структуры данных и методы доступа. Пример тому, OLAP-кубы. Для них необходим специальный алгоритм, который повысил бы эффективность доступа в среде трансляции.
Особенности доступа к сводным OLAP-таблицам следующие:
Планировщик трансляции сводных таблиц по запросу (Summary Tables On-DemandBroadcastScheduler,STOBS-?)
Этот алгоритм состоит из двух компонентов — нормализующего компонента, который учитывает первые две из перечисленных выше особенностей сводных таблиц, и ?-параметра, который позволяет транслировать одни и те же данные нескольким клиентам.
Сервер собирает запросы клиентов по мере их поступления. Для каждого запроса QX к сводной таблице TX рассчитываются следующие показатели:
При решении какую таблицу отправить следующей сервер выбирает запрос с максимальным значением параметра (RхA)/S.
Параметр ? определяет меру гибкости при передаче сводной таблицы и ликвидирует из очереди трансляции несколько зависимых от нее таблиц. Например, если ? = 2 и сервер выбирает для трансляции таблицу TX, то из очереди удаляются все запросы на любую таблицу TY, которая в решетке поиска находится двумя уровнями ниже и может быть выведена из TX (см. рис. 2 — таблица, которую можно вывести из другой, всегда находится ниже последней).
Формально, TY может и не транслироваться в случае передачи TX, если Y
X и |X| – |Y| ?? . Следовательно, клиент может использовать таблицу TX, включающую изначально запрашиваемую им таблицу TY, если Y
X и |X| – |Y| ??.
Значение a меняется в диапазоне от нуля до максимального размера куба данных — MAX. Если ?= 0, то никакой гибкости в использовании сводных таблиц нет, и доступ клиента возможен только при точном соответствии. Если a = MAX, то клиенту передается первая же таблица, включающая его исходный запрос. В случаях, когда 0 < ? < MAX, транслируется первая таблица, включающая исходную и расположенная в решетке куба на a уровней выше.
Проводя различия между STOBS-? и алгоритмами, требующими точного соответствия запросу, назовем описанные выше алгоритмы строгими (STOBS-0 также относится к этой категории), а семейство STOBS-?, где ? > 0, назовем гибкими.
При этом, значение ? известно серверу и клиентам (оно может входить в дескриптор таблицы).
В качестве примера рассмотрим решетку, показанную на рис. 3 (в ее узлах расположены сводные таблицы). QX — запрос на четырехмерную таблицу (d1, d2, d3, d4). Допустим, что узлы решетки, показанные на рисунке — это таблицы, на которые есть по крайней мере один запрос. Пусть ? = 2. Также предположим, что для трансляции выбрана таблица TX, соответствующая запросу QX. Тогда клиенты, запросившие таблицы (d1, d2), (d1, d3), (d1, d2, d3) и (d1, d2, d4) будут удовлетворены таблицей TX, а запросившие таблицы (d1), (d2), (d3) и (d4) будут ждать следующего цикла трансляции.
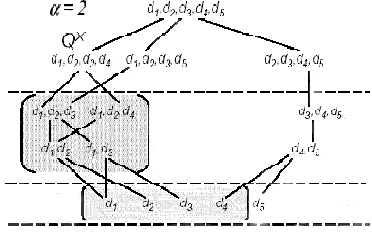
Рис. 3 Гибкость алгоритма.
Параметр (RхA)/S учитывает все факторы, влияющие на время доступа, параметр aопределяет меру гибкости алгоритма. Преимущество гибкого подхода к трансляции состоит в том, что удовлетворяется запрос клиента не только в случае точного соответствия. Недостаток — лишнее время, которое тратит клиент, прослушивая в канале детальную, а не сводную таблицу. Выбрав разумное значение ?, можно найти приемлемый баланс между сокращением времени ожидания и увеличением времени прослушивания.